Data Quality, Low-Code Analytics Tools, & Data Network Effects: Some Reflections


One of the more interesting threads I’ve uncovered these weeks - in both my own work and across the data-adjacent literature - has been the notion of poor data quality, feedback loops, and the data product. For instance, what impact does bad data - say, inaccurate or missing values - have on your product? Whose responsibility is it to evaluate and improve these data? And is manually updating these data the best use of your team’s time?
Being deeply embedded in product and operations, I personally feel the pain when regularly performing analytics, to say nothing of the many challenges my data and product friends face. So why the urgency and excitement on the topic? I see three reasons.
1. Poor data quality is ubiquitous and pernicious
Whether you work in a large company or a bootstrapped startup, you will encounter instances in which your data is inaccurate, incomplete, inconsistent, and - broadly - not reliable. Having high levels of poor data quality will impact your business and bottom line. We all know this.
2. Too few people within the organization have the tools to diagnose data quality
Companies hold huge sums of data and maintaining them is costly and labor intensive, much of which falls under the purview of a DataOps or Data Engineer professional. Too few organizations have access to this level of data expertise nor share the tooling to evaluate internal data. This challenge calls for both (1) cross-functional collaboration and (2) innovative BI products that allow non-technical users to regularly perform audits, discover gaps, and create pathways for overall data improvements.
3.Feedback (growth) loops and data network effects are essential to provide a self-sustaining and compounded growth
When you discover gaps, revising existing data fields is time consuming and periodic, in addition to directly imposing restrictions to scale and creating continuous value for your profit. Of course, human data quality checks - often typically conducted through analytics - are essential. However, data teams must reach further. The more teams build automation into their “growth loops”, they will directly benefit from data network effects and getting the flywheel effect going.
My goal in this blog is to introduce some of my own thoughts on data quality within the context of feedback loops and data management. The scope of this work sits at the intersection of product and data operations. Therefore, I will not feign domain expertise in DevOps nor Data Engineering, recognizing that I am primarily concerned with strategy and novel approaches to data management.
If you work with product data and have an interest in growth loops, read on!
The Ubiquitousness of poor data quality
For any PM (among other professionals), data and analytics are simple table stakes, which would otherwise be impossible without trustworthy data. Tracking, collating, analyzing, and extracting insights from user data resides at the bottom of the product pyramid, such that it behooves all of us to answer questions like: How are users actually using the product? Where are the bottlenecks in my product funnel? Can I better make decisions using A/B tests between different cohorts? And what can I do to improve their experience?
Figure 1 : Dimensions of Data Quality
However, the expansiveness of data quality presents multiple challenges (see Sadiq’s handbook for a more exhaustive overview). Basing any decision on data that may be inaccurate, incomplete, inconsistent, or simply not reliable, will impact the company and resources you spend. These may be rooted in areas like (1) human error, creating outliers (see below); (2) outdated data; (3) missing data and much more. These challenges present major roadblock for any PM building or monitoring the health of a new or pre-existing product.
Figures 2 and 3: Outliers Impacting Data Distribution (source)
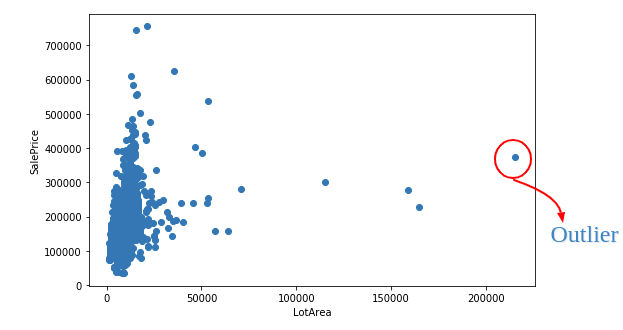
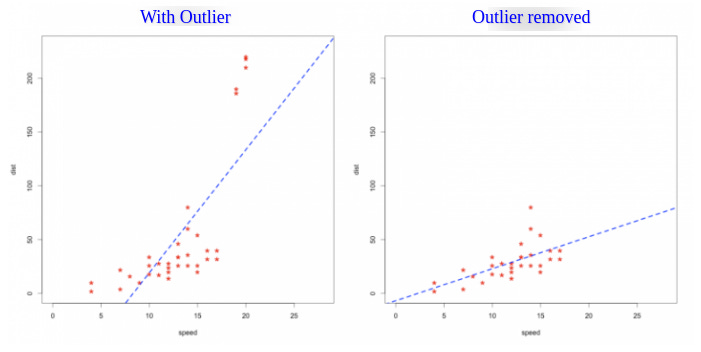
The existence of data quality is of course idiosyncratic in nature, but also rooted in organizational inefficiencies that otherwise could be resolved through better tooling. In the next section, I’ll discuss some of these challenges and upcoming data product opportunities.
Too few people within the organization have the tools to diagnose data quality
What I want to emphasize here isn’t the inevitability of data challenges. Rather, it is the fact that too few people within organizations have the tools or know-how in order to diagnose data quality.
A major step toward improving organizational data would be equipping more people at the company with the support and tools given the cross functional nature of data quality issues. This presents a huge opportunity for the SaaS market and the democratization of data using innovative tooling and products. A handful of proprietary and open source tools already exist (e.g., Talend, OpenRefine, and many more). However, tons of products haven’t even penetrated the market - which is good news for the consumer!
One area of tooling that I’m particularly excited about is the advent of low- and no-code tools and its impact on digital transformation. Briefly, low-code tools aim to make programming easier, faster, and more available to a much broader audience, such that users do not have to program application tools in the conventional way. The core functionality is accessible through a visual interface and guided interface, along with pre-built integrations with other tools to exchange information as needed.
Within the context of data access and low-code tools, a shoutout to my friend’s company, Covalent, whose product leverages the power of large language models like GPT-3 that make it easy for anyone to “write” a SQL query and build quick data visualizations. By enabling users to audit their data through easy and manageable queries, low-code tools like Covalent quickly help identify anomalies and opportunities. It is outside the scope of this article to discuss audits at length, but I’ve included a summary of them in the appendix.
Figure 2: Example query using Metabase
With many companies lacking human resources (e.g., DevOps, Data Engineers, etc.) to continuously perform data-quality checks, leveraging off-the-shelf tools to audit these data may offer easier alternatives to teams. As Kurt Bollacker of StitchFix contends: “Data that is loved tends to survive.”
How Growth Loops and Data Network Effects Can Lead to Better Results
Performing audits on company data is an essential activity for every team. But what are the solutions?
Without wading too far into the territory of my incredible Data Engineer and DevOps colleagues, I’ll offer two simple alternatives: (1) fixing the source data; or (2) leverage data network effects. There is a multitude of resources on data evaluation and its adjacent approaches (e.g., data lineage, data lifecycles, etc.). However, I’d to divulge in the second, more product focused approach.
Imagine you are faced with the following.
You have a network of 200 engaged users, but require continuous daily investment to ensure that their data is high integrity (e.g., manually updating records, reaching out to team members to double check values, etc.).
You have a network of 100 users but invest in an initiative that automatically solicits information from these members. With the right incentives, users respond and contribute to new and richer data points, which you reinvest back into the product - say, a recommender system. The product accrues value, more people join, and the cycle continues as you organically expand the user base two fold each week.
This concept is closely to to the widely discussed data network effects (nfx) and Brian Balfour’s Reforge concepts on micro and macro growth loops. Their key characteristics: they are closed systems, such that inputs produce outputs that get directly reinvested into inputs. Moreover, they compound and improve in efficacy over time.
Figure 5: Data Network Effects Growth Loop
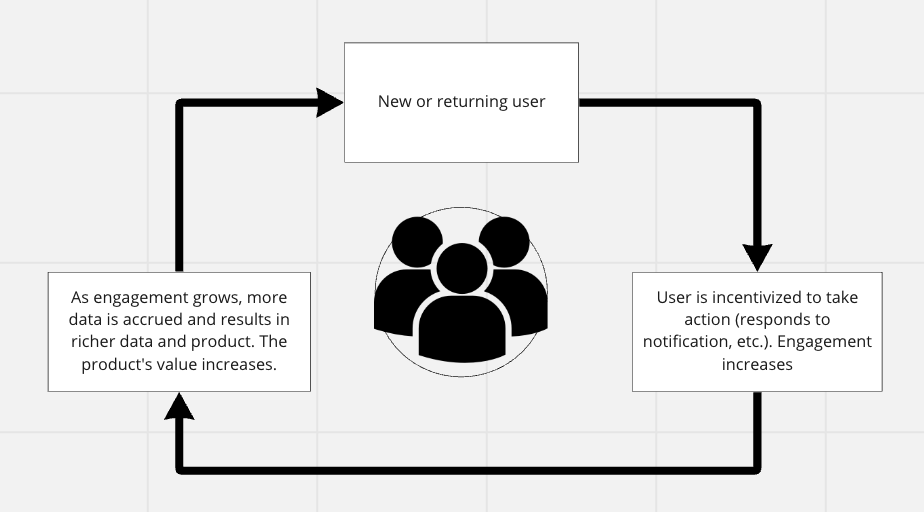
As opposed to the manual “learning” from data - typically done through analytics with human analysts doing much of the work - data nfx requires at least some level of automated productization of the learning. The quality or cost of the product improves as more data is collected. The benefits are multiple. First, they provide a scale defensibility against new entrants, such that the value of incremental data doesn’t asymptote quickly. This makes makes it hard for competitors to provide the same value without a similar size user base. And second, the more automation you are able to build into the loop, the more likely you are to get a flywheel effect going.
You’re most likely familiar with the concept of data nfx and examples found at the feature - as opposed to the core business level. For instance, consider recommendation engines, such as Amazon, Netflix, LinkedIn, and many more across every industry vertical. The more data these products acquire, the better they are at serving users, ingesting more data and - concomitantly - accruing more value.
Here are a few other examples:
Upwork: New and existing users join platform to freelance, soliciting and completing projects across different areas. New data (e.g., client experience, rate, completed projects, reviews, etc) are used to inform recommendation tool to surface other candidates to clients. Freelance labor returns and client returns because of satisfactory experience. Cycle continues.
Glassdoor: As new and returning users visit platform, company and salary information are collected. Users are incentivized to submit additional information, increasing the product value, which is then re-shared to existing or new users via Google searches. Cycle continues.
Stripe: New and existing users visit platform. As user base grows, Stripe capture more completed transactions, informing models to detect fraudulent transactions.
So where to begin if you want to bake in the defensibility of data nfx?
Data nfx are typically challenging to begin and sustain because they require a complete shift in a company’s focus - that is, its core element is the “data” product. This first involves building the right type of data infrastructure (e.g., data platforms, tooling, etc.) and then having the right data team in place.
One of the biggest challenges, however, is the cold start problem. You need to have actual data to enjoy the benefits from data nfx. The cold start challenge can be more or less challenging depending on the context of your product. In my own personal conundrums, I’m currently entertaining simple search and filtering functionalities that benefit from both a breadth and depth of user data. Other products are more interested in deep learning algorithms, which need much larger sums of data.
Of course there are multiple methods to acquire data. Some data can be collected internally, such as a simulation of user data or their manual entry. Other data, depending on the product use case, can be externally, including web scraping, outside vendors, among many other approaches. However, as the Data Product guru, Eric Weber, maintains, rather than focusing on the data itself, we should also be asking, “what is the value proposition of data for your product, and how does it lead to improving the product?”.
One of the hardest exercises is to think small and build something that delivers real and tangible value to users from the beginning. And then you incite them to start contributing their data. So how do you take that first step to deliver tangible value? What problem are you actually trying to solve? And how might (the right type of) automation add both value and defensibility to your product?
I’ll leave these concluding thoughts here, creating space for additional reflections to surface in the coming weeks.
Resources:
New O’Reilly handbook on Data Quality Fundamentals
A decent video summary of Data Quality by IBM
ORCAA’s framework for conducting a Data Audit
Matt Turk’s Data Network Effects seminal blog
Reforge’s Growth Loops concept